Recursive Language Models (RLM): What They Are and How to Use Them
A clear intro to recursive language models, where they help, where they fail, and practical patterns for safe use.
- rlmagent-reasoningverificationai-agents
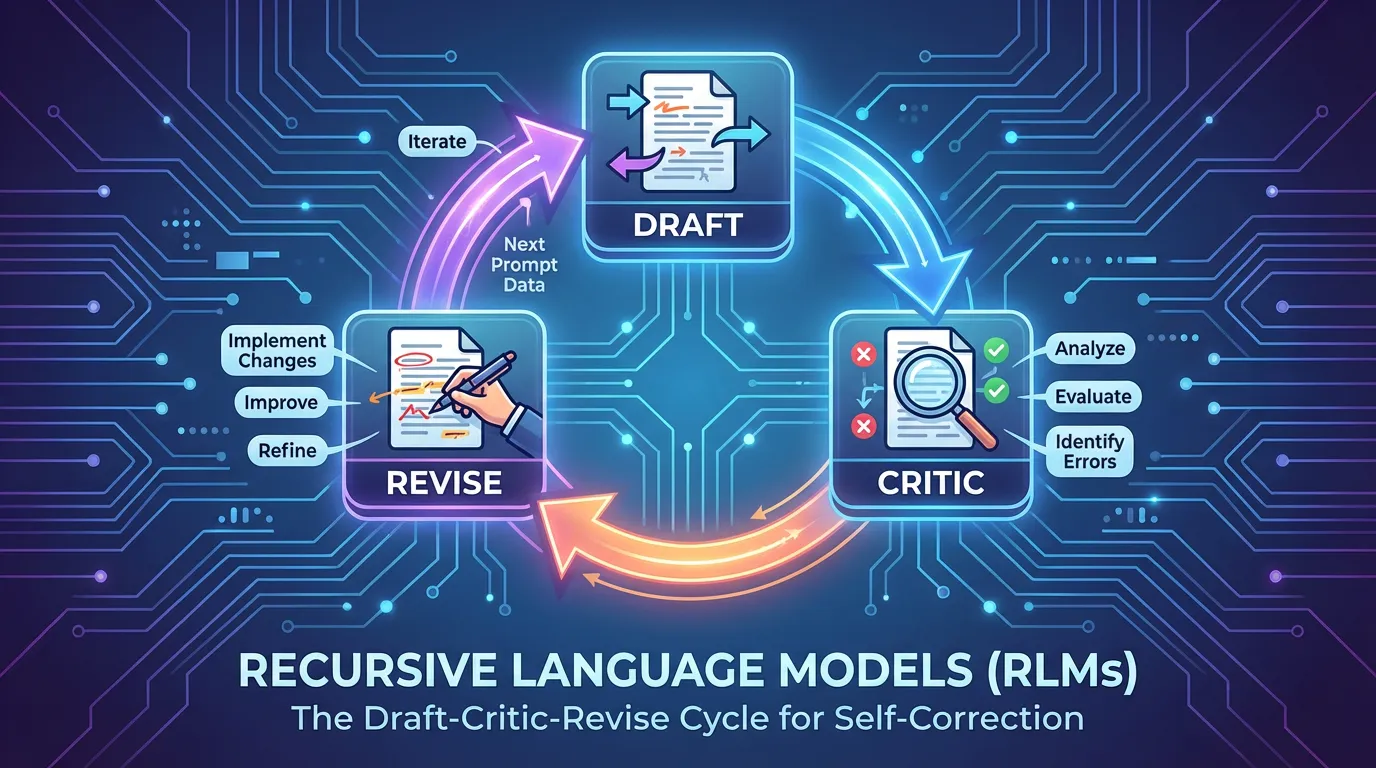
Self-correction is the holy grail of agentic workflows. Recursive Language Models (RLMs) achieve this by treating their previous output as "draft data" for the next prompt. By looping through a "Draft -> Critic -> Revise" cycle, these models can catch their own syntax errors and logical fallacies before a human ever sees the code.
Direct answer: Recursive language models reuse their own output to refine answers across multiple steps. They significantly improve results when tasks are well-scoped and verification criteria are objective, but they can amplify mistakes if the initial context is flawed. Use decomposition and independent verification steps to keep recursion grounded and safe.
RLM in plain English
An RLM is a workflow where a model produces a draft, evaluates it, and then uses that evaluation to produce a better result. The recursion can be simple or multi-stage.
How recursion changes reasoning
Recursion forces the model to check its own work. Instead of one pass, it iterates through a plan, a draft, and a verification step. This reduces blind guesses when the context is clear.
Where RLMs shine
RLMs work well for complex tasks that benefit from reflection: multi-step designs, refactors, or synthesis work. They are also strong when you can provide a stable source of truth, such as your docs.
Where RLMs fail
If the initial context is wrong, recursion repeats the same error. If the evaluation criteria are vague, the model can optimize for the wrong goal. This is why verification and constraints matter.
Implementation patterns
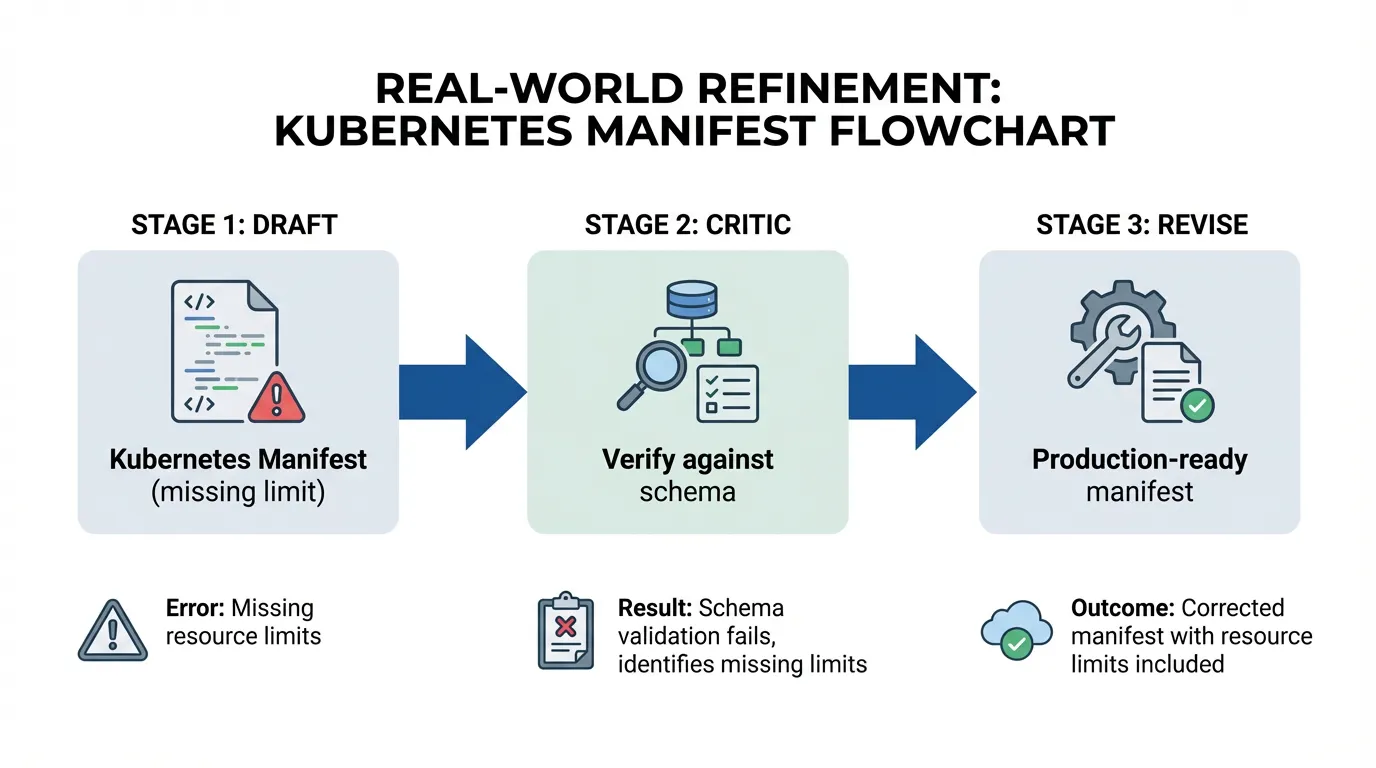
Real-world refinement: An agent was asked to write a complex Kubernetes manifest. In the first pass (Draft), it missed a required resource limit. In the second pass (Critic), it was prompted to "Verify this manifest against the internal K8s schema". It identified the missing limit itself and produced a corrected, production-ready manifest in the third pass (Revise).
Use simple patterns before you build complex loops.
Task decomposition
Break the problem into clear sub-tasks with explicit success criteria. Each step should be testable.
Verification loops
Add a check that validates the output against known rules. A quick test suite or lint pass can reveal errors early.
Evaluation and safeguards
Track accuracy against a baseline like your benchmarks. Add guardrails for security-sensitive tasks and document constraints in security.
Example metrics to track:
| Metric | What it tells you | How to measure | |---|---|---| | Revision pass rate | Quality of recursive refinement | Percent of outputs that improve after a second pass | | Error carryover | Whether mistakes persist | Issues that appear in multiple passes | | Verification failures | Safety gaps | Count of failed checks per run |
FAQs
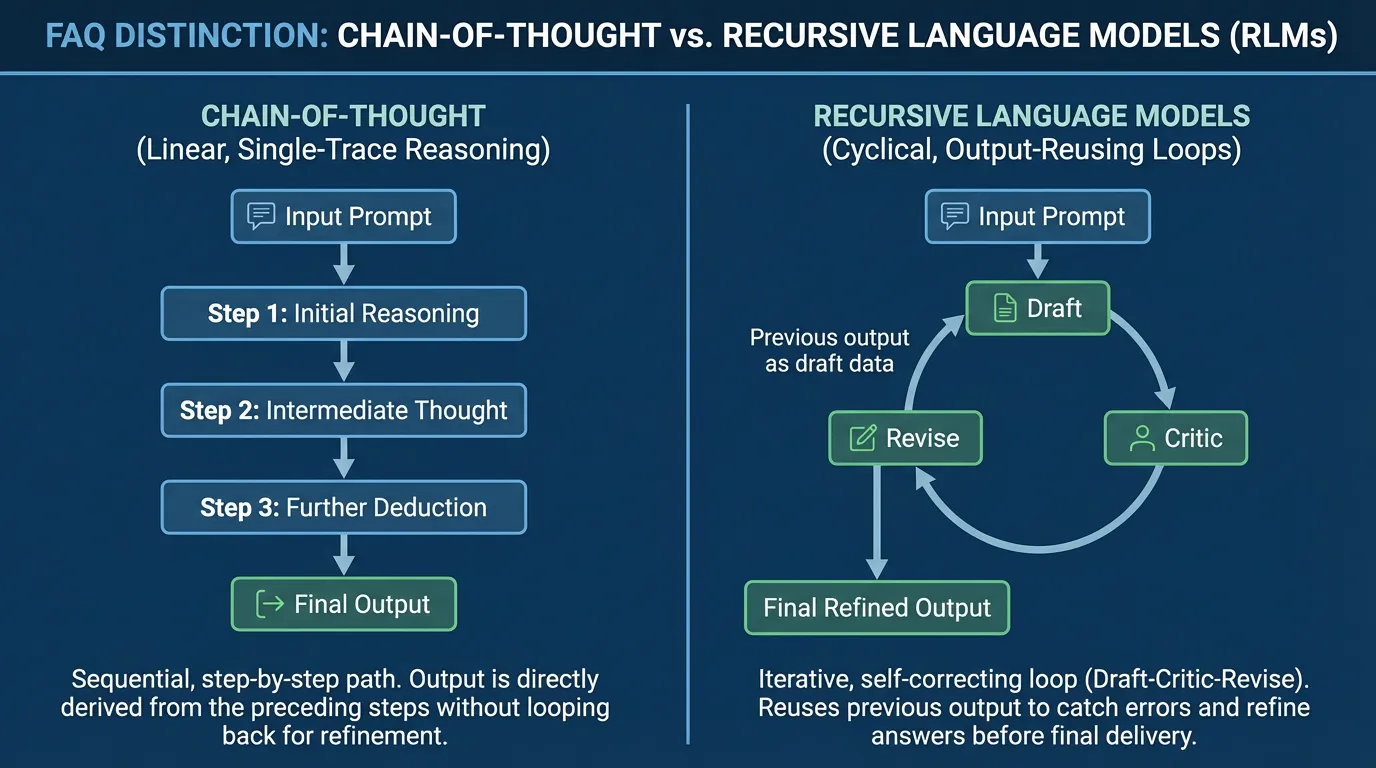
Are RLMs the same as chain-of-thought?
No. RLMs describe a workflow that reuses outputs across steps, not just a single reasoning trace. The value comes from iteration and verification, not hidden reasoning.
When should I avoid recursion?
Avoid recursion when the initial context is weak or noisy. In that case, repeating the process can reinforce the same mistake.
The RLM Cycle: A 3-Step Success Path
To make recursion work, follow this sequence:
- Draft: Generate the initial solution based on provided context.
- Verify: Check the output against an objective source of truth (e.g., Linter, Schema).
- Refine: Rewrite based specifically on the verification feedback.
Stop hoping for a "smart" model and start building a recursive process.
Ready to build self-correcting workflows? Try for free.
Ready to give SotaDocs a try?
A clear intro to recursive language models, where they help, where they fail, and practical patterns for safe use.