Measuring Agent Answer Quality: A Practical Evaluation Framework
A practical framework for measuring agent answer quality with gold standards, scoring rubrics, and feedback loops.
- evaluationanswer-qualitybenchmarksai-agents
If you do not measure agent quality, you cannot improve it. The best teams use a simple evaluation framework with clear gold standards and repeatable checks.
This guide explains what to measure, how to build a scoring rubric, and how to create feedback loops that improve outcomes.
Direct answer: Measuring agent answer quality requires gold standard tasks, a clear scoring rubric, and repeatable checks. Combine human review with automated tests to catch errors and track trends over time. This turns agent output into a system you can improve. Start small and iterate.
What to measure
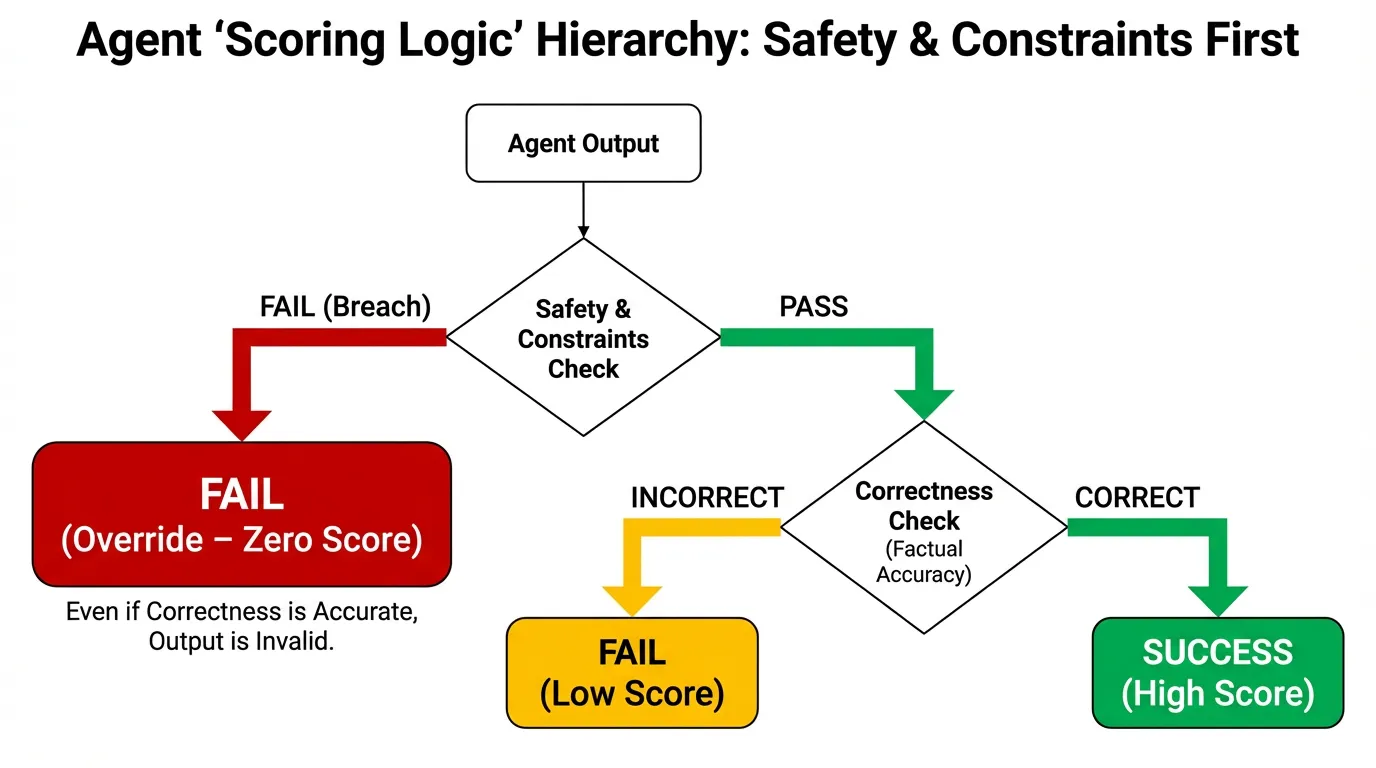
Focus on correctness, completeness, and safety. A correct answer that violates constraints is still a failure.
Example metrics to track:
| Metric | What it tells you | How to measure | |---|---|---| | Correctness | If answers are right | Compare to gold standard | | Constraint adherence | If rules were followed | Check for required constraints | | Safety issues | Policy violations | Count flagged outputs |
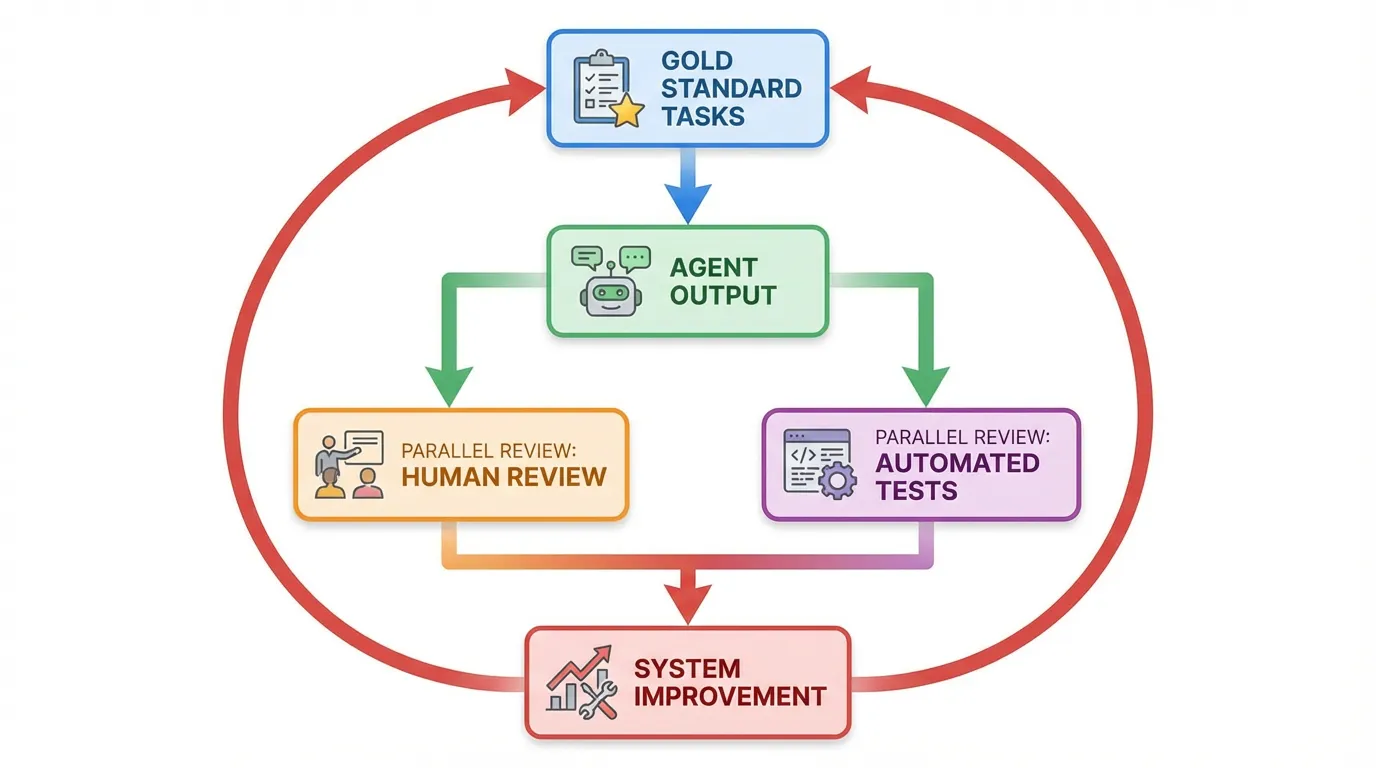
Define gold standards
Create a small set of tasks with known correct answers. Keep them in a stable place in your docs or internal reference.
Example (hypothetical): A gold standard task requires a specific API call. The agent output is scored against the expected call and flagged when a deprecated field appears.
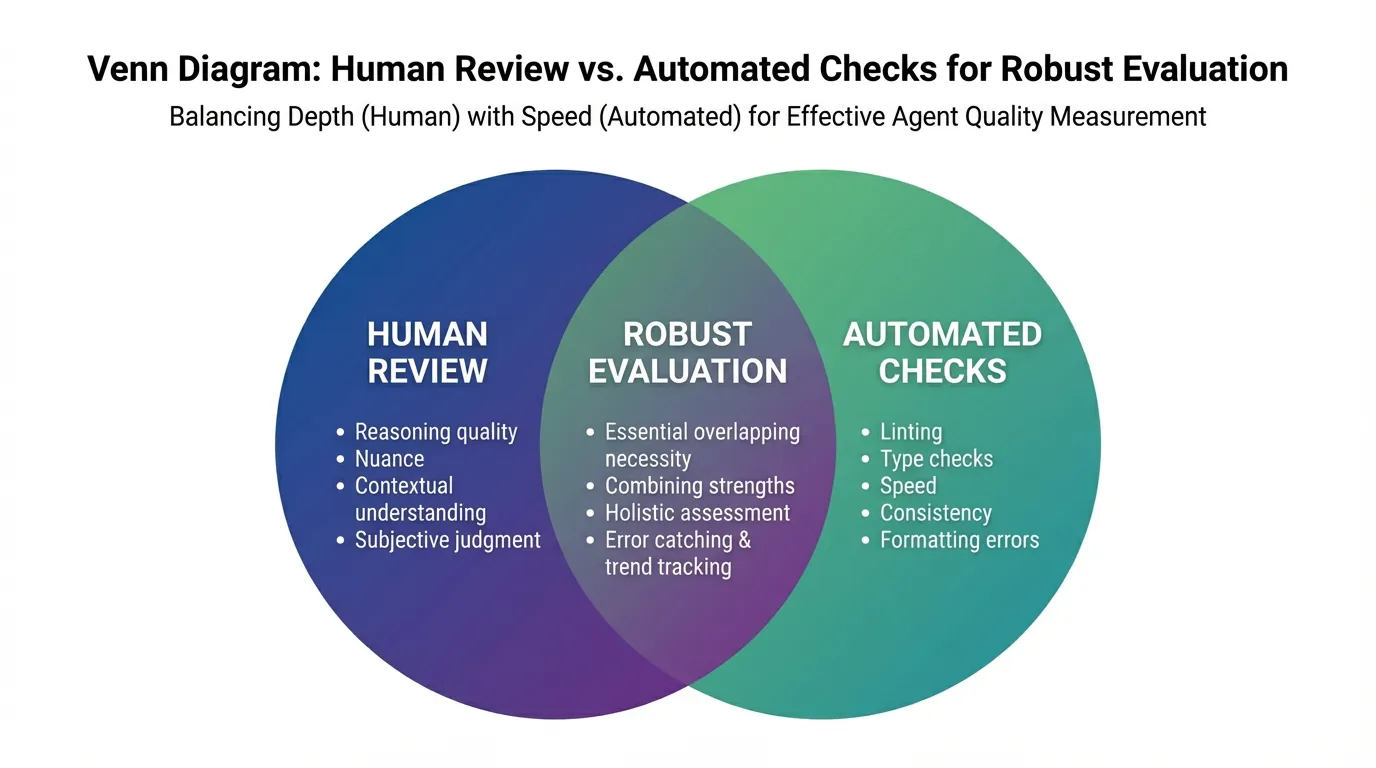
Evaluation methods
Use a mix of human review and automated checks.
Human review
Review outputs for reasoning quality and adherence to requirements. This catches issues that tests miss.
Automated checks
Run lint, type checks, and tests. Track failures and categorize the root cause.
A scoring rubric that works
Use simple categories such as correct, partially correct, and incorrect. Add a separate score for safety and policy compliance.
Feedback loops and ownership
Assign owners to fix the top failure modes. Use a baseline from benchmarks and track progress over time.
Reporting and iteration
Report quality trends weekly or monthly. Tie improvements to documentation and prompt updates.
FAQs
How many gold tasks do I need?
Start with 10 to 20 tasks that cover the most common workflows. Expand only after you can run them reliably.
Can I automate evaluation?
Yes. Use lint, tests, and structured checks for objective scoring, then add human review for edge cases.
Summary and next step
Key takeaways:
- Gold standards and rubrics make quality measurable.
- Combine human review with automated checks.
- Use feedback loops to improve over time.
Ready to apply this? Try for free.
Ready to give SotaDocs a try?
A practical framework for measuring agent answer quality with gold standards, scoring rubrics, and feedback loops.