Building a Documentation Pipeline for AI-First Development
A practical guide to building an AI-first documentation pipeline, from sources of truth to publishing, QA, and maintenance.
- documentation-pipelineai-firstworkflowcontext
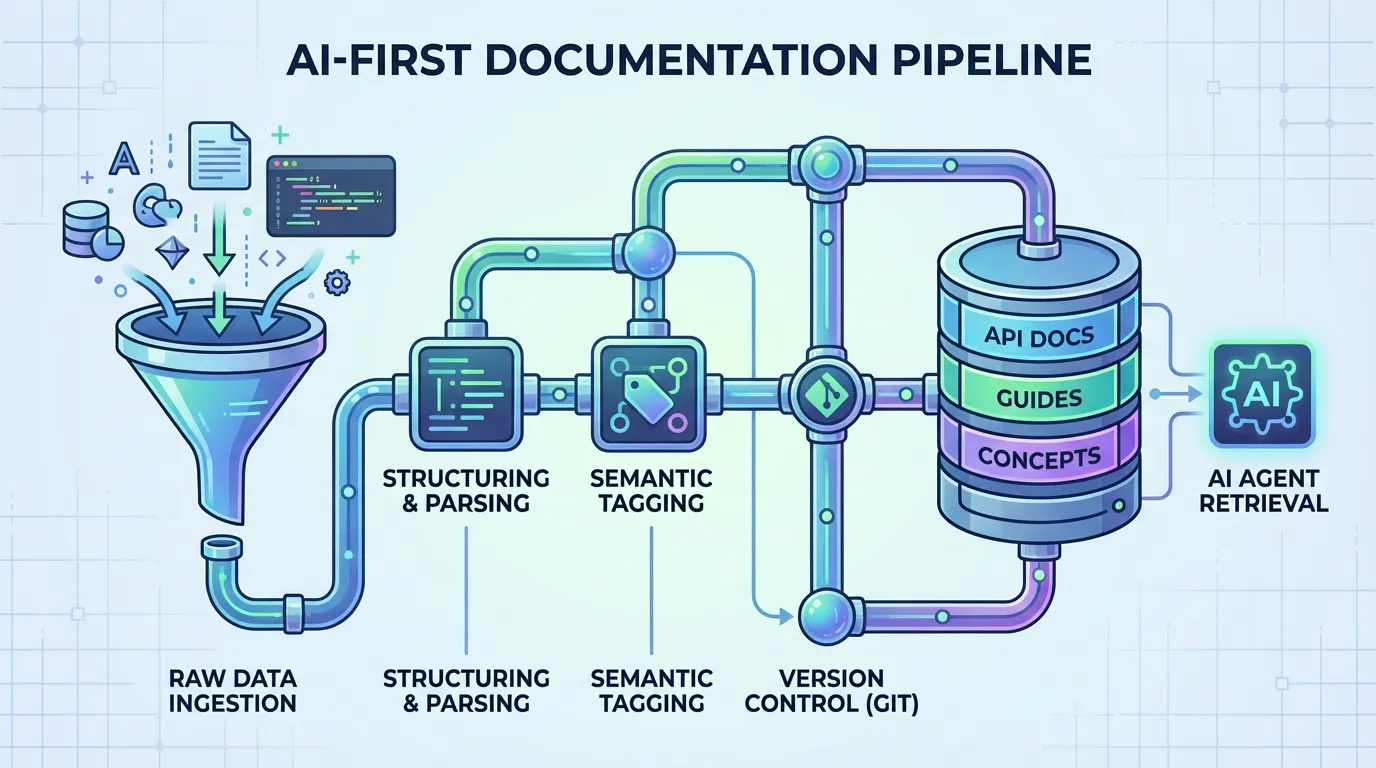
AI-first development requires a documentation pipeline that is structured, current, and easy for agents to retrieve. Without a pipeline, context drifts and quality drops.
This guide shows how to build a doc pipeline that supports agents and keeps content reliable.
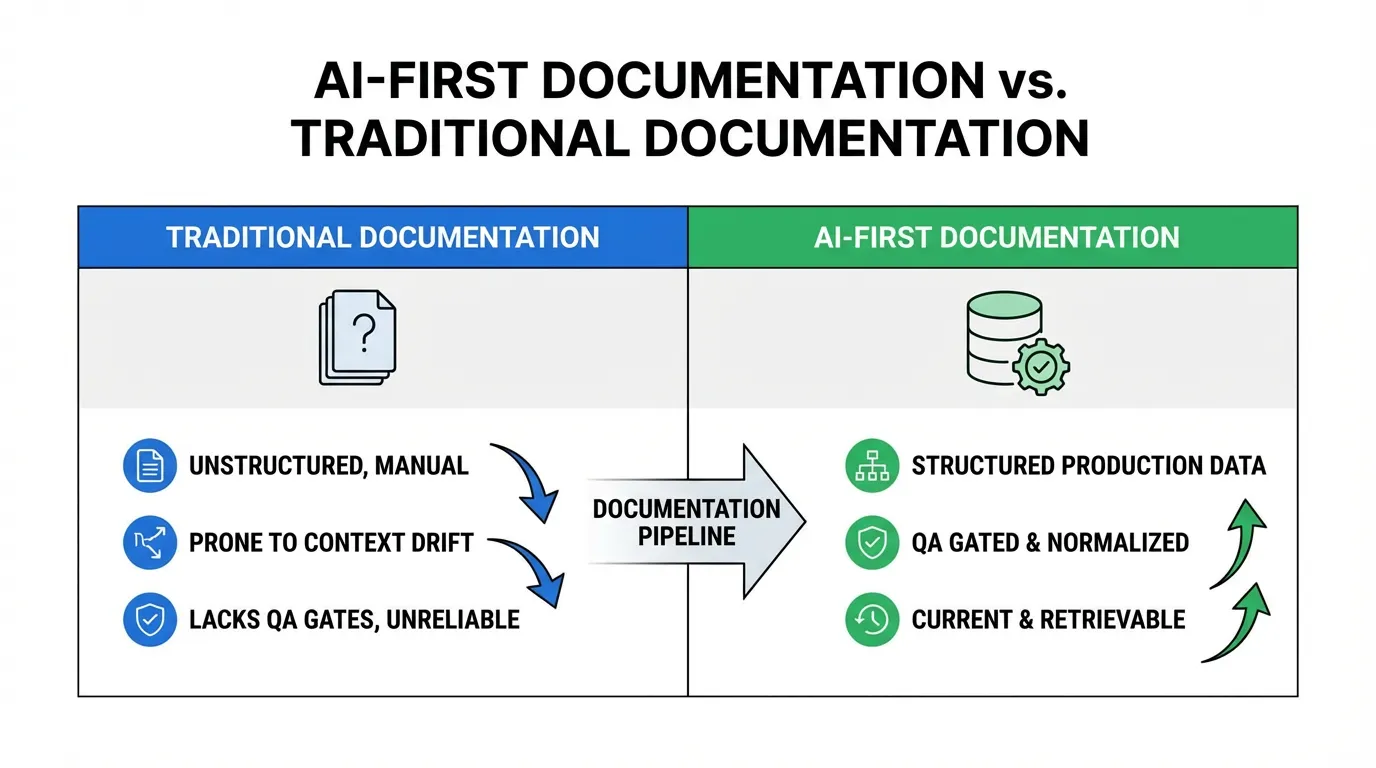
Direct answer: An AI-first documentation pipeline treats docs like production data with clear sources of truth, normalization, and QA gates. It keeps context current and retrievable for agents, which reduces errors and rework. Without a pipeline, drift accumulates quickly. Start small and scale.
What an AI-first doc pipeline is
An AI-first doc pipeline treats documentation as production data. It has sources of truth, clear ownership, and quality gates.
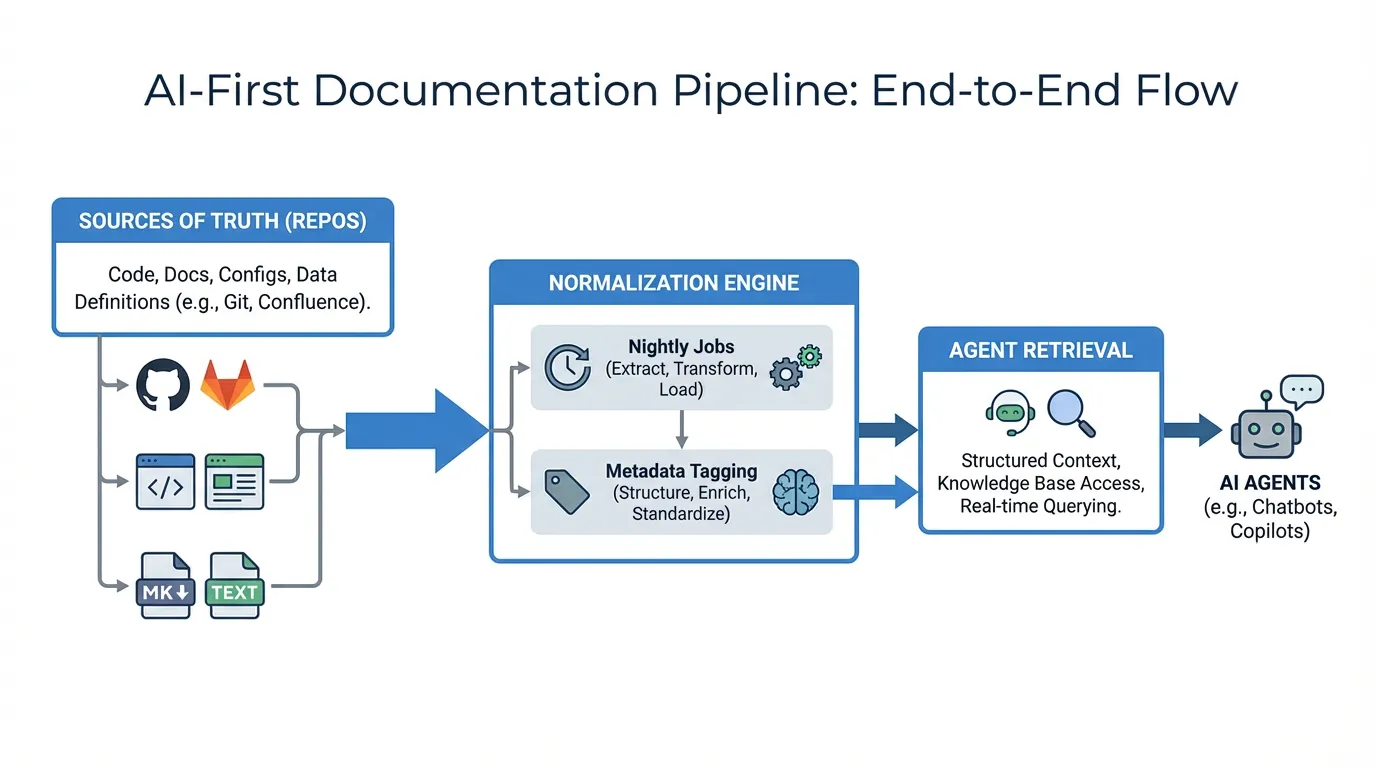
Inputs and sources of truth
Start with a canonical source such as your docs. Decide which repositories and teams own each section.
Processing and normalization
Normalize formatting, add metadata, and use consistent identifiers. This improves retrieval and reduces ambiguity.
Example (hypothetical): A nightly job normalizes Markdown and updates metadata, so retrieval always sees the latest version tag.
Publishing and indexing
Publish docs in predictable locations and ensure they are indexed. If your workflows depend on tools, align with integrations.
Quality gates and reviews
Add checks for broken examples, deprecated APIs, and missing constraints. Tie these checks into release workflows.
Pipeline checklist
- Source of truth is defined and owned.
- Metadata includes version and owner.
- QA checks run before publishing.
- Drift audits are scheduled.
Maintenance and ownership
Assign owners, set review schedules, and measure drift. For sensitive systems, align updates with security.
Step-by-step rollout
- Define the source of truth and owners.
- Normalize content and add metadata.
- Publish and index with QA checks.
- Review monthly and adjust workflows based on failures.
Example metrics to track
| Metric | What it tells you | How to measure | |---|---|---| | Doc freshness | Recency of updates | Days since last update on key pages | | QA pass rate | Quality of docs | Percent of checks passing | | Retrieval success | Pipeline impact | Correct context in agent output |
FAQs
What is the minimum viable pipeline?
Start with a single source of truth, basic metadata, and one QA check. You can add automation once the workflow is stable.
Who should own the pipeline?
Ownership should sit with the team responsible for documentation quality. In many orgs, that is a docs or platform team.
Summary and next step
Key takeaways:
- Pipelines keep docs current and retrievable.
- Normalize content and add QA gates.
- Ownership prevents drift.
Ready to apply this? Try for free.
Ready to give SotaDocs a try?
A practical guide to building an AI-first documentation pipeline, from sources of truth to publishing, QA, and maintenance.